台北醫學大學 陳宏霖博士
1. 網路搜尋相關文獻以製作影片內容。
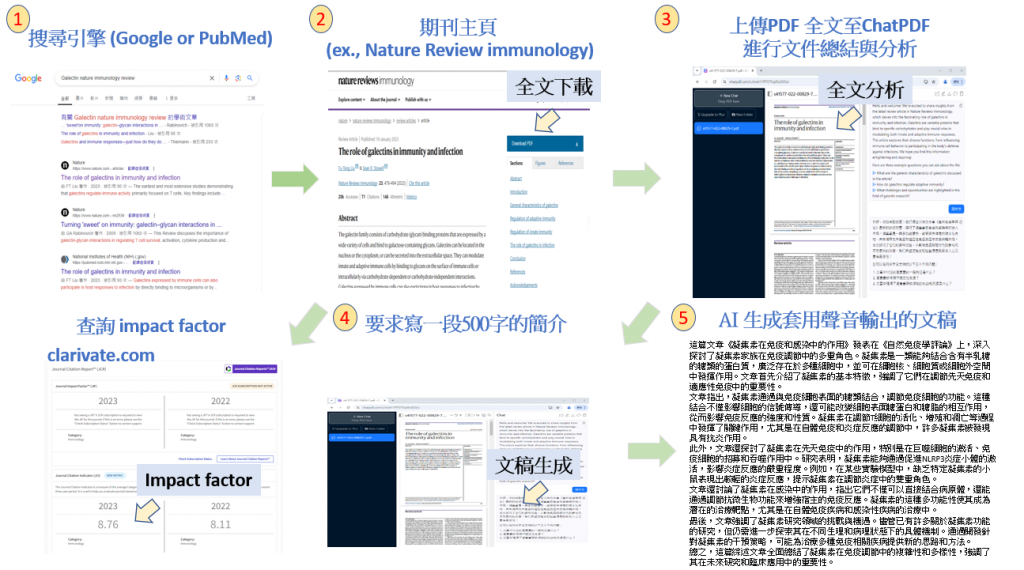
在製作影片之前,首先需要找到與主題相關的科學文獻。這些文獻將提供必要的背景知識和研究結果,幫助我們更好地理解主題並撰寫影片內容。
使用軟體
搜尋引擎:使用Google Scholar、PubMed或其他學術搜尋引擎,輸入關鍵字(如「半乳醣凝集素 免疫」)來查找相關的學術文章。
篩選文獻:根據發表日期、引用次數和期刊影響力等標準,篩選出最相關和最具權威性的文獻。
下載PDF:找到合適的文章後,下載其PDF文件以便後續分析和製作內容簡介。
結果輸出
完成文獻搜尋後,將所選的PDF文件上傳至ChatPDF或其他文本分析工具,提取關鍵信息,並生成簡介或解說內容,為影片製作奠定基礎。這樣可以確保影片內容的準確性和學術性。
由於我是做半乳醣凝集素(galectins)的相關研究的, 所以這次舉例我想要錄製一個影片, 來解說一篇介紹半乳醣凝集素的相關文獻, 的相關流程。
2. 製作個人化的替身,並結合聲音合成, 與影像合成技術。
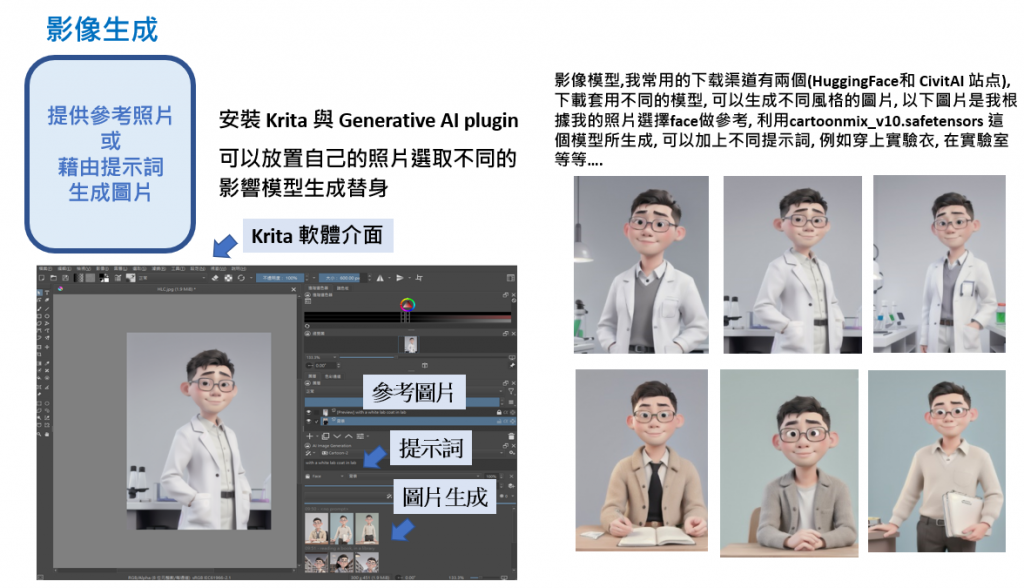
在影片製作中,個人化的替身可以增強觀眾的參與感和互動性。透過影像生成軟體和聲音合成工具,我們可以創建一個獨特的虛擬角色,並使其在影片中表現出來。
影像生成:
下載並安裝Krita及其Generative AI插件。
使用自己的照片作為參考,選擇不同的影者模型生成替身的圖像。
下載影像模型,常用的下載渠道包括HuggingFace和CivitAI,選擇適合的模型生成不同風格的圖片。
Krita 安裝:
https://krita.org/zh-tw/download
AI 插件安裝:
https://github.com/Acly/krita-ai-diffusion
由於YouTube 上已經有很多想關的影片介紹Krita AI 圖生圖, 與圖更換背景與人物的簡介, 所以我就不在另外介紹, 但是提供以下相關教學連結給大家參考:
AI功能安裝
https://www.youtube.com/watch?v=ttXF9HPcvRw&t=318s
AI繪圖教學
https://www.youtube.com/watch?v=-BgYW4g8E0Q&t=7s
3. 聲音合成:
選擇一款聲音合成AI工具(利用一段之前的錄音來訓練模型之後, 就可以利用模型來唸出文稿, 我使用的軟體是 GPT-SoVITS 將影片內容輸入到聲音合成工具中,生成與替身相符的語音。
軟體安裝和操作, 可以根據github網頁上的資訊進行, 我是使用windows 系統, 也完全沒有問題
網路上已經有很多教程如下:
以下是摘錄自上面網頁 大致上軟體的使用流程如下
步驟 1: 安裝 GPT-SoVITS
• 本地安裝選項:
o Windows: 下載官方整合包,運行 go-webui.bat。
o Mac: 建議使用 Colab 以避免安裝問題。
• 啟動程式:
o 點擊「執行階段 → 全部執行」以開始下載和安裝。
o 允許所有警告和授權提示。
o 確認安裝成功後可見「Running on public URL」。
步驟 2: 提供訓練的聲音素材
• 聲音素材要求:
o 1~2 分鐘的中文聲音素材,格式為「.wav」,無背景噪音。
• 上傳聲音檔:
o 在 Google Drive 中建立「voice_files」資料夾及其子資料夾「raw」和「slicer」。
o 將聲音檔上傳至「raw」資料夾。
• 切割聲音檔:
o 複製聲音檔和分割聲音的資料夾路徑,並在 GPT-SoVITS 網頁上進行切割。
步驟 3: 檢查語音識別是否準確
• 標記語音識別文件:
o 複製 slicer_list 路徑並貼到「.list annotation file path」。
o 勾選「Open labelling WebUI」以進行標記和檢查準確性。
步驟 4: 將訓練的資料格式化
• 格式化資料:
o 在 GPT-SoVITS 網頁中填寫模型名稱及相關路徑。
o 點擊「Start one-click formatting」以完成資料格式化。
步驟 5: 微調訓練
• 開始訓練:
o 點擊「1B-Fine-tuned training」,依序啟動 SoVITS 和 GPT 訓練。
o 提醒使用者下載完成的檔案以防資料丟失。
步驟 6: 推理,輸入文字生成聲音
• 進行推理:
o 進入「1C-inference」分頁,刷新模型路徑。
o 點擊「Open TTS inference WEBUI」以生成聲音。
• 下載生成音頻:
o 提供生成音頻的下載選項,並鼓勵使用者試聽。

4. 影像聲音合併合成
準備好了上面的聲音檔, 接下來就是準備一段影片, 由於我們是使用Krita 生成的替身圖檔, 我們可以利用螢幕錄影軟體, 打開圖片, 錄製一段影片(我常用的免費螢幕錄影軟體如Ocam 就是一套簡單的螢幕錄影錄音免費軟體)
https://github.com/vinthony/video-retalking.git
按照GitHub的指示, 安裝所有需求的軟體後就可使用, 使用也是相當方便, 只要執行以下程式:
python3 inference.py \
--face examples/face/臉部影像.mp4 \
--audio examples/audio/聲音檔案.wav \
--outfile results/合併結果.mp4
5. 製作投影片
我們可以把這篇文章中的圖表和網路上搜尋的圖片資料做成投影片
也可以再利用ChatPDF 提供圖片的解釋與翻譯
我們可以簡單利用Microsoft PowerPoint 軟體, 把PDF檔案中的圖片,貼到PPT上進行編輯, 如對圖片內容不清楚或是需要翻譯, 也可以在進入ChatPDF 進行詢問, 只要在PDF文件中選取部分區域或文字, 就會出先文字提示, 可以選擇解釋。

6. AI 音樂生成
給一段文字, 生成音樂
(因為只能給少於200個字作歌曲創作, 所以我用ChatPDF生成的第一段話)
(如需下載檔案需要註冊與付費)
以下式網頁生成的歌詞內容:
凝集的力量
凝集素 在細胞中存在
結合糖類 沒有空白
核內發揮 外部也不敗
散步在 身體的每個地帶
先天免疫 它來掌控
適應免疫 不會拋空
重要角色 不容忽視
在免疫中 一直保持
……….
(我們之後把這段音樂變成片尾曲)
上傳到YouTube 可以發現AI創作的音樂沒有版權的問題
7. 影像剪輯
現在有很多影片剪輯軟體都有附上AI功能, 可以協助放字幕, 我這次是使用威力導演, 網路上有很多教學和相關資料,如下:https://reurl.cc/GpDMgA
為了放入投影片和剛剛做好的, 替身配音影片, 我們可以使用子母畫面的功能 ~ 威力導演下載:https://tw.cyberlink.com/downloads/trials/powerdirector-video-editing-software/download_zh_TW.html
8. 螢幕錄影錄音軟體
在很多時候需要將螢幕的影像或是聲音錄影,錄音, 這時候介紹一個方便好用的免費軟體
Ocam (註: 使用免費軟體, 會有廣告跳出喔!)
Ocam 下載網址:https://www.azofreeware.com/p/ocam.html
後記
在這次的分享影片的製作中,我們探討了如何使用AI工具來進行語音合成的過程。這些內容純屬於我個人的學習與查詢經驗,並不涉及任何商業軟體的廣告或推廣。所有資源均來自於網路上的公開資訊,旨在與大家分享我在學習過程中的收穫與心得。
需要特別提醒的是,部分軟體在運行時需要使用GPU,因此如果您打算在個人電腦上安裝這些工具,請務必確認您的電腦配備了NVIDIA顯卡,以確保能夠順利運行。希望這段分享能對有興趣的朋友們有所幫助,並激發更多人探索AI技術的潛力!